DataFrame groupby agg style bar
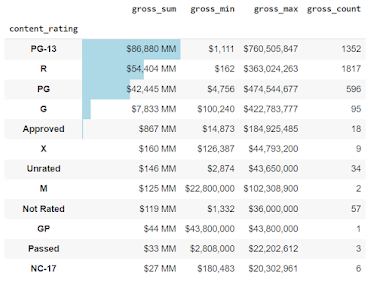
The goal of the article is to investigate the bar function through the style method of Pandas DataFrame. So, when we work with DataFrames, we can create a visual within a DataFrame. What does that mean? We can embed bar charts, sparklines, and mini bar charts in the DataFrame. This can reduce the amount of cognitive load when reviewing a DataFrame. Google Colab link with all the code To get started, we are going to import the data: import pandas as pd import numpy as np import pandas_profiling as pp loc = 'https://raw.githubusercontent.com/aew5044/Python---Public/main/movie.csv' m = pd.read_csv(loc) pd.set_option('display.max_columns',None) pd.options.display.min_rows = 10 Next, I want to create a new DataFrame that groups by the rating (e.g., "R" "PG-13"), then calculates the total sum, min, max, and total observations for gross. content = ( m .groupby('content_rating') .agg({'gross':['sum','min...